The Portal Problem: Where Freight Scheduling Automation Breaks, and How We Fixed It

If you're evaluating freight scheduling automation, one of the biggest challenges to navigate is portal scheduling websites. The key question:
Will my scheduling automation tools reliably work across dozens of different portal websites?
Every vendor claims they can automate appointment scheduling. The real test comes when a shipment needs appointments booked in Costco, Retail Link, Lineage, Manhattan, C3, Uber Freight, E2Open, or one of the hundreds of other web portals that warehouses, retailers, brokers, and carriers use every day.
These portals aren't just browser tabs your operations team keeps open permanently. They're often the point where otherwise promising automation projects break down and teams get pulled back into manual work.
The bottom line: if your automation platform can't reliably navigate portals, it can't really automate scheduling. And when it comes to number of portals supported, there is a clear difference between HubFlow and other platforms:
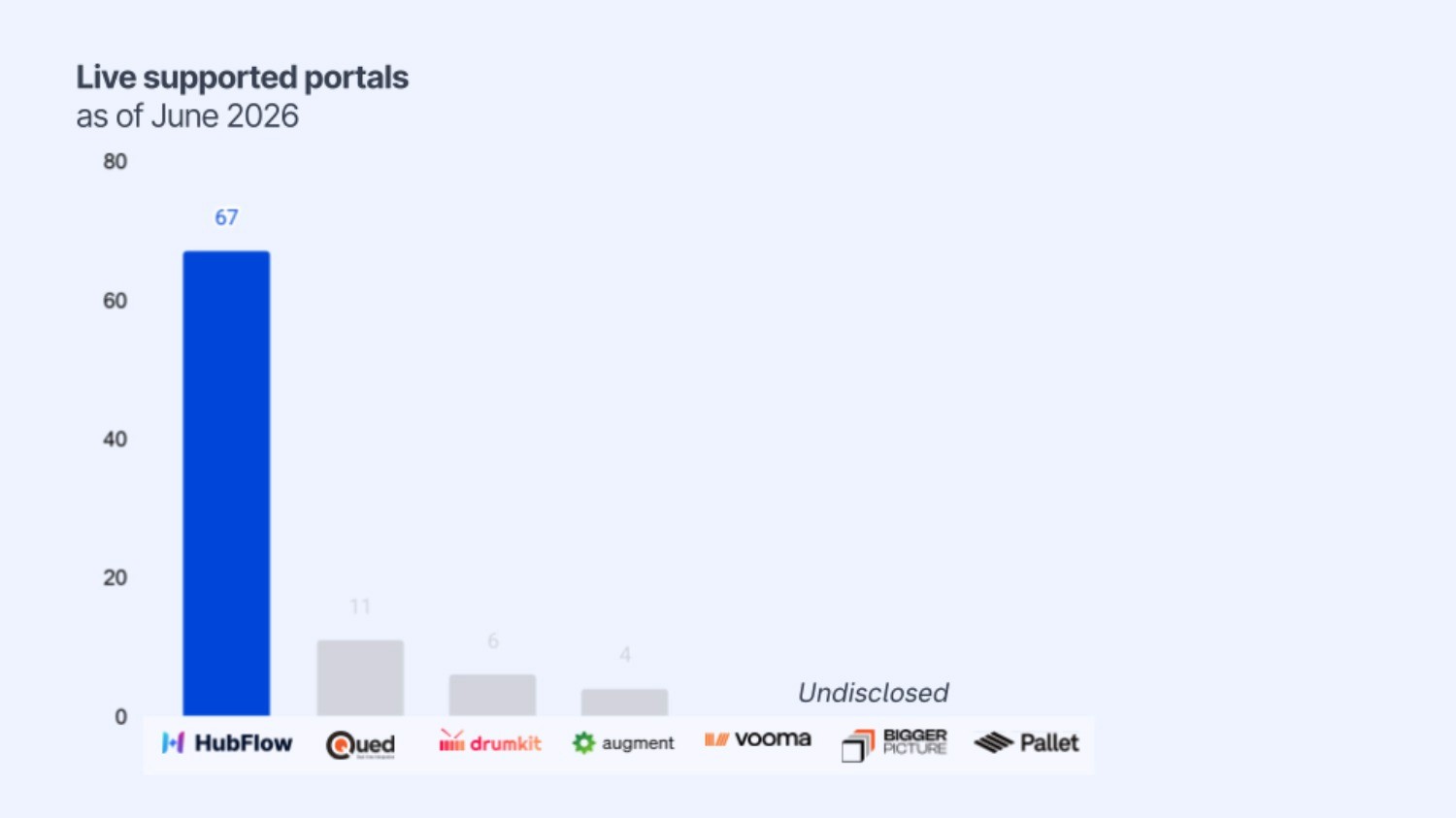
Over the last 18 months at HubFlow, we’ve built scheduling automation across nearly 70 different freight scheduling portals. Along the way, we've learned a lot about what makes browser automation work – and why traditional approaches struggle to scale.
This article explains how we think about portal automation, why traditional robotic process automation (RPA) has been difficult to deploy and maintain for logistics use cases, and how AI-based browser automation is changing what's possible.
Why I'm skeptical of traditional browser automation
Before HubFlow, I spent 5 years at Uber Freight, where my team built and operated a small army of bidding bots that bid on billions of dollars of freight across 50+ different shipper TMSs and spot boards.
Entering spot bids is a workflow with almost zero tolerance for error – for our team, mistakes meant either missing out on revenue, or accidentally winning loads at negative margin by entering a bad rate. (And yes – winning a load at negative margin was actually considered a mistake at Uber Freight, at least by the time I was working on spot bidding in 2021-2024.)
As a result, my team spent a lot of time thinking about how browser automation actually works in real-world logistics environments. I got to geek out with some of the best engineers and data scientists in the world over how to automate routine work in shipper TMSs and other logistics websites.
By necessity, I had to learn a lot about how TMS portals work (or don’t), and how to build bots that could run reliably across a wide range of industry websites. Some of these were built by tech startups and changed constantly. Others hadn’t been updated since the Clinton administration. Many had edge cases that only appeared after thousands of interactions.
My main takeaway from that experience: browser automation in logistics was very difficult and expensive to operate at scale. The only use cases that could support it were high-cost, high-ROI deployments like our spot bidding bots.
Why only large companies could afford bots
When I left Uber Freight and started HubFlow in 2024, I knew browser automation would be a core part of whatever we built.
What I didn't know was how we would be able to afford it as a startup.
At Uber, we used robotic process automation (RPA) to build our bidding bots. I was familiar with the economics of spinning up RPA, and they were quite challenging for a startup like HubFlow:
RPA license costs ran into the 6 figures and sometimes over $1M – and that was fixed cost, before any automation was deployed
Each new portal automation required 2-3 weeks of expensive engineering work
For every 20 or so automations we built, we had a full-time engineer maintaining them
The maintenance costs were the sneakiest. If anything on a target website changed – even something as simple as a button moving or options changing in a dropdown menu – it took more engineering time to fix and re-test each bot. It was almost like we were building each bot over from scratch.
The result was that at Uber Freight, we had a team of engineers whose full-time job was to build and maintain RPA bot “integrations” to spot boards. These integrations were brittle – almost always, at least one bot was down for maintenance – and given the cost, it was hard to justify building them for lower-volume websites.
The root cause of expensive automation
This isn't a criticism of RPA. It's simply how traditional browser automation works.
RPA automations are highly deterministic. They click specific buttons, navigate specific screens, and follow predefined workflows.
That makes them reliable when nothing changes and when every use case follows the exact same workflow. But the reality is, logistics portals and workflows change constantly. Particularly in scheduling, new websites and workflows are being introduced all the time.
And even in those portals that haven’t changed for decades, old and poorly maintained websites often exhibit unexpected behavior, which once again increases engineering costs and decreases reliability.
If the only way to respond to all these changes is to involve engineering, automation becomes very expensive to maintain.
For buyers evaluating automation vendors, this explains why many automation projects start to slow down once you touch portals. You start to see:
Long implementation timelines
Significant engineering involvement
Frequent “exceptions” when automation fails
Limited portal coverage
Slow rollout of new automations
The problem isn't necessarily your vendor. The problem is the underlying technology.
The challenge: there is no 80/20 rule in scheduling
With HubFlow, we decided to focus on scheduling. Going in, we knew it was a workflow that had been very resistant to automation, and big part of why it was hard was because scheduling involved navigating a large number of portals.
The logic was simple: in order to schedule an entire shipment, you had to be able to schedule every stop. And in order to schedule every stop, you had to be able to automate scheduling for every long-tail portal.
Within our initial group of design partners, we quickly identified that there were over 200 unique portal websites being used to schedule freight. These ranged from standalone apps like Opendock to retailer-operated sites like Walmart’s RetailLink and Costco’s scheduler, to modules of a TMS like E2Open and Uber Freight, to homegrown automation like Outlook calendar forms.
The problem was getting worse, because new portals were being added every day as warehouses migrated off of email and adopted new dock scheduling technology:

Before building anything, we tried to estimate the size of the “portal problem” as it related to browser automation. There were:
At least 200 portals that we knew about were being used to schedule freight
At least 4 workflows per portal: book, modify, reschedule, and cancel
Multiple variants of each portal depending on customer type, carrier type, shipment type, or account permissions. For example, there are a dozen different versions of both C3 and Manhattan, and asset carriers and brokers will see different workflows in the same portal.
If you’re doing the math at home, that’s over 1,600 different portal automations just to support scheduling (200 websites x 4 workflows x 2 versions of each workflow) – and that’s a conservative estimate.
My team at Uber Freight spent millions of dollars and had half a dozen full time employees supporting a few dozen RPA bots, and each bot took 2-3 weeks to build.
We realized that if we built all of the browser automation we needed using traditional RPA-based methods, HubFlow would run out of both time and money.
In order for us to fulfill our mission and solve freight scheduling once and for all, we had to find a better way.
AI browser automation: the major unlock
By sheer luck, we happened to start HubFlow at the exact moment a Renaissance was happening in the world of browser automation.
January 2025 was a milestone month: both Browser Use and OpenAI’s Operator were released to the world, and it became clear that there was a better way to automate repetitive tasks on the web than building traditional RPA bots.
The first time we saw this in practice was in March 2025. One of our customers needed Retail Link automation, and I built a working AI browser agent in roughly 30 minutes. We had it running in production the next day. (I am not an engineer).
That was the moment it became obvious that deployment speeds had fundamentally changed. As we built more of these automations, we also gained conviction that AI was becoming more accurate and reliable than traditional RPA.
The hard part: making AI reliable
AI browser automation is much faster to spin up, but introduces a new challenge: maintaining accuracy.
RPA bots are perfectly predictable and deterministic. They will click on the same exact button on every run. This determinism is also what causes them to fail frequently and require expensive maintenance – the bot doesn’t notice or care if the website has changed and the button has moved or disappeared.
This is why state of the art RPA in freight scheduling has a success rate of around 85%. It works 85% of the time… every time. The other 15% are exceptions or errors that your team has to handle.
AI browser automation is probabilistic – it might work fine 95 times out of 100. But on the other 5, it could do something completely random, like get lost and Google “how to schedule a Costco freight appointment.” (During our early testing, I watched this happen with our AI a few times – it was funny, but definitely not production-ready).
95% accuracy isn’t good enough for freight. If we screw up scheduling, a truck shows up at the warehouse at the wrong time or on the wrong date. TONUs, detention, and layover fines get paid. Customers get angry.
Building an “automation library”
To close this gap and reduce the number of exceptions we send to logistics operations teams, we built what we call an “automation library.” Every successful scheduling session becomes a resource that the AI agent can learn from and reference in the future.
When HubFlow needs to complete a portal task, our patent pending self-improving AI can:
Reference previous sessions + workflows
Compare its current state to historical runs
Reuse proven automation sequences
Recall prior exception resolutions
Dynamically choose the best model or tool for the task
For example, when we encounter a brand-new portal, we may use a more advanced reasoning model to work through the workflow.
Once that workflow has been successfully completed, future runs can reference the proven path and verify that each step remains consistent.
If something changes, the automation can compare the new situation against previous examples and determine the best recovery path.
This gives us the best of both worlds. HubFlow’s browser automation is:
Fast to deploy (because AI builds new automation from a single successful run)
Low-cost to build and maintain (because the “maintenance” is AI-assisted)
Reliable and accurate (because the AI can tap into past successes and exception resolutions)
The compounding advantage of scale
The most interesting part of this approach is what happens over time.
As HubFlow adds more portals, more workflows, and schedules more volume, the library of automations that our AI can draw on continues to grow.
Because we are scheduling everywhere, we will always have the most up-to-date workflow for every version of every portal. HubFlow customers will enjoy more portal coverage, higher accuracy/uptime, instant self-healing, and the lowest price per portal automation from any provider.
The more scheduling activity flows through our platform, the more capable and lower-cost the platform becomes.
That's not a marketing slogan – it's a natural consequence of how our system is designed.
The future of scheduling automation
For years, browser automation was limited by the economics of RPA. This put a damper on most attempts to automate scheduling.
18 months ago, AI browser automation changed the equation. Now, instead of building one-off bots using engineering resources that are expensive, slow, and unreliable, we're building a system that learns from every scheduling workflow it completes.
Our goal isn't simply to automate a handful of portals – our goal is to automate scheduling everywhere. We believe that required a fundamentally different approach to browser automation, so we built it.